Skalierbarkeit von KI-Anwendungen in der ProduktionFertigung zwischen Insellösungen und systemübergreifenden Produktionsanlagen
Lesedauer: 7 Minuten
|

Bereits heute existieren vereinzelt vielversprechende industrielle Anwendungen der Künstlichen Intelligenz, vor allem in den Bereichen Prozess- und Zustandsüberwachung. Heutige KI-Modelle werden jedoch ausschließlich als Insellösungen für einen Prozess und eine Maschine entwickelt. Durch heterogene Produktionsanlagen existieren kaum prozess- und zustandsübergreifend anwendbare KI-Modelle. Wie gelingt daher eine breite Übertrag- und Skalierbarkeit der Anwendungen in der gesamten Produktion? Dies erfolgt einerseits durch die Vereinheitlichung der Informationsmodelle verschiedener Maschinen durch intelligente Parameteridentifikation (Crawling) sowie in einem zweiten Schritt durch eine Datensegmentierung zum Aufbau strukturierter Datenbasen (Clustering). Auf Grundlage von kontextbasieren Datenbasen, die aus einem einheitlichen Informationsmodell aus unterschiedlichsten Maschinen entstehen, können KI-Ansätze skaliert und auf die gesamte Produktion übertragen werden.
Ein zentraler Anwendungsfall bei der Verwendung von KI-Modellen ist die Zustandsüberwachung von Produktions- und Handhabungsmaschinen. Durch die Aufzeichnung von verschiedenen Zustandsgrößen wird die Basis zur weiteren Datenanalyse gewährleistet. Die benötigten Parameter wie Positionsdaten und Motorstromsignale können aus der Steuerung gewonnen werden und stehen beispielsweise auf einem auf der Steuerung aufbauenden OPC UA-Server zur Verfügung. Da die Parameter auf OPC UA-Servern durch eine fehlende Standardisierung häufig proprietär strukturiert sind und proprietäre Semantiken verwenden, kann ihre Identifikation und Zuordnung eine Herausforderung darstellen. Erforderlich ist daher ein Hilfswerkzeug, das die benötigten Parameter in OPC-Namensräumen durch intelligentes Crawling identifiziert und mit einem einheitlichen Maschineninformationsmodell verknüpft, um dem Anwender die notwendigen Parameterwerte in einer standardisierten, für ihn passenden Struktur zur Verfügung zu stellen.
Ziel der Crawler-Anwendung ist es, für jeden benötigten Parameter des Maschineninformationsmodells eine Knotenstrukturverbindung zu den Datenquellen im OPC-Server zu fi nden, um auch unbekannte Maschinen in kürzester Zeit erfassen und hinsichtlich ihrer Parameter aufklären zu können. Die Identifi kation der Parameter erfolgt dabei wie in Gönnheimer et al. 2019 beschrieben zum einen analytisch, zum anderen mit Hilfe von Verfahren des Maschinellen Lernens [1].

Die Crawler-Anwendung ermittelt dabei für den jeweils gesuchten Parameter die Zugehörigkeitswahrscheinlichkeit mit allen betrachteten Datenknoten und ordnet die bestbewertete Datenquelle dem Parameter zu.
Nach der Identifikation der relevanten Parameter ist eine weitere intelligente Hilfsfunktion notwendig, um KI-Ansätze ganzheitlich in der Produktion nutzen zu können. Dabei ist die Erkennung wiederkehrender Bearbeitungsmuster (im Folgenden auch Zyklus genannt) in Zeitreihen ausschlaggebend.
Mit Hilfe dieser Funktion kann so beispielsweise der Kraftanstieg, gemessen über einen Dehnungsmessstreifen, oder das Abreißen eines Kühlschmierstofffilms bei einer Werkzeugmaschine, bezogen auf den dazugehörigen Bewegungsverlauf der Maschine im wiederkehrenden Verlauf, detektiert werden. Eine weitestgehend autonome Mustererkennung kann hier einen deutlichen Informationsgewinn darstellen und dazu beitragen Verschleiß, Standzeiten oder auch den Energieverbrauch zu optimieren. Im vorliegenden Artikel wird eine Möglichkeit zur intelligenten Datenstrukturierung auf Basis einer Mustererkennung vorgestellt.
Ausgangssituation
An einer Produktionsmaschine werden eine Vielzahl an Signalen gemessen, welche als Datengrundlage einer Mustererkennung dienen können. Dabei ist zu beachten, dass die Erkennung wiederkehrender Muster dazu dient, repetitive Tätigkeiten oder charakteristische Signalverläufe in den Messdaten zu entdecken und deren Auftreten kontextbasiert darzustellen. Der Anwender kennt hierbei zwar den groben Prozess, jedoch sind die genauen Musterverläufe, deren Länge, Abfolge und Häufigkeit meist nur sehr begrenzt bekannt. In diesem Fall scheitern klassische Auswertungen und Analyseverfahren, wie zum Beispiel die schwellwertbasierte Anomalieerkennung, da das Anwenderwissen zu gering ist, um Vorgaben für solche Verfahren festlegen zu können.
Die Datensegmentierung erfolgt in drei sequentiell ablaufenden Phasen (siehe Bild 1). In Phase 1 werden in historischen Daten Segmente erkannt sowie diesen Kontextinformationen als weitere Signale zugewiesen. In der zweiten Phase erfolgt online eine Segmenterkennung sowie in der darauffolgenden Phase der Abgleich von historisch gelernten und online erkannten Segmenten. Auf Basis dieses Abgleichs können Prozessüberwachungen als auch aufbauende KI-Funktionen realisiert werden. Als Kernelement wird die Datensegmentierung in historischen Daten an einem Validierungsbeispiel im Folgenden näher betrachtet. Ablauf und Funktionsweise ist in Bild 2 sichtbar und wird in Netzer et al. 2019 beschrieben.
Stand der Technik
Die Mustererkennung in Zeitreihen bildet im Gegensatz zu anderen Anwendungen der Mustererkennung ein junges Forschungsfeld und findet erst seit der Jahrtausendwende große Beachtung in der Literatur. Das Interesse und die Intensität der Forschungsaktivitäten sind seitdem jedoch außergewöhnlich hoch. Bereits im Jahr 2003 existierten mindestens 1000 wissenschaftliche Publikationen im Bereich der Mustererkennung in Zeitreihen [3].
Das Erkennen wiederkehrender Muster in den Signaldaten von Produktions- und Handhabungsmaschinen findet abseits generischer Ansätze aber bisher kaum Beachtung. Der prominenteste Anwendungsfall der Zyklenerkennung an Produktions- und Handhabungsmaschinen ist die Erkennung von wiederkehrenden Energieverbrauchsmuster [4]. Zur Prozessüberwachung wird dieser Ansatz bislang nicht angewendet. Daher besteht in diesem Bereich noch weiterführender Forschungsbedarf.
Anwendung
Die Validierung des Algorithmus erfolgt an einem Anwendungsfall des laserstrahlunterstützten Stanzens von Stahlblechen an einer Produktions- und Handhabungsmaschine. Bei diesem Verfahren spielt das Absorptionsverhalten der Laserstrahlung durch die Blechoberfläche eine wichtige Rolle. Hierbei ist vor allem der Einfluss auf den Temperaturverlauf ein wichtiges Kriterium für die Auslegung und Optimierung der Lasertechnologie und des Stanzvorgangs [5].
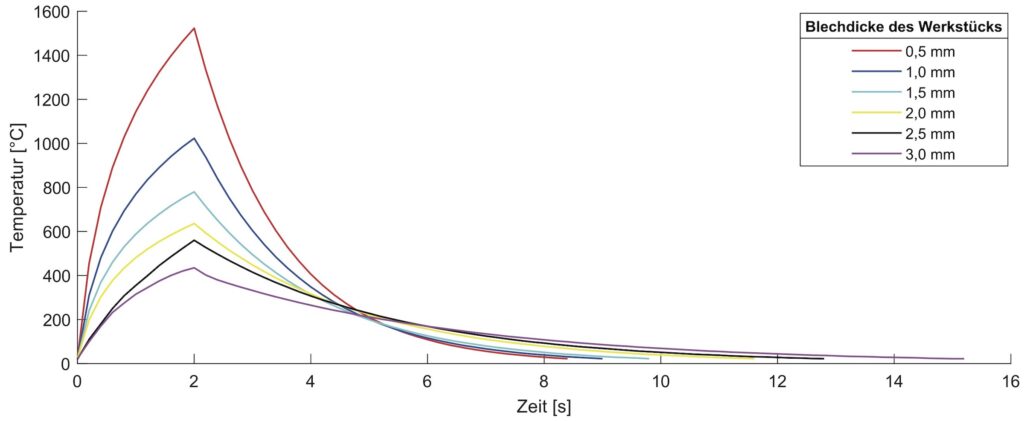
Verschiedene Blechdicken und Materialien weisen hierbei unterschiedliches Erwärmungs- und Abkühlverhalten auf. Über die Steuereinheit der Produktions- und Handhabungsmaschine kann der Temperaturverlauf der Werkstücke berührungslos mit einem Quotientenpyrometer gemessen und aufgezeichnet werden. Um rückwirkend erkennen zu können, welche Werkstücke in welcher Quantität bearbeitet wurden, wird der beschriebene Algorithmus angewendet, um wiederkehrende Temperaturverläufe den Blechdicken und damit den Werkstücken zuordnen zu können. Dies kann Grundlage für angegliederte Verfahren, wie zum Beispiel eine Prozess- und Energieoptimierung, oder auch eine Anomalieerkennung sein.
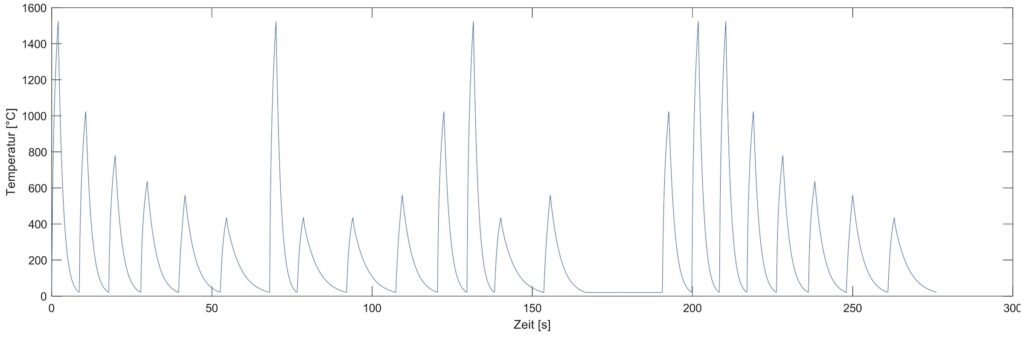
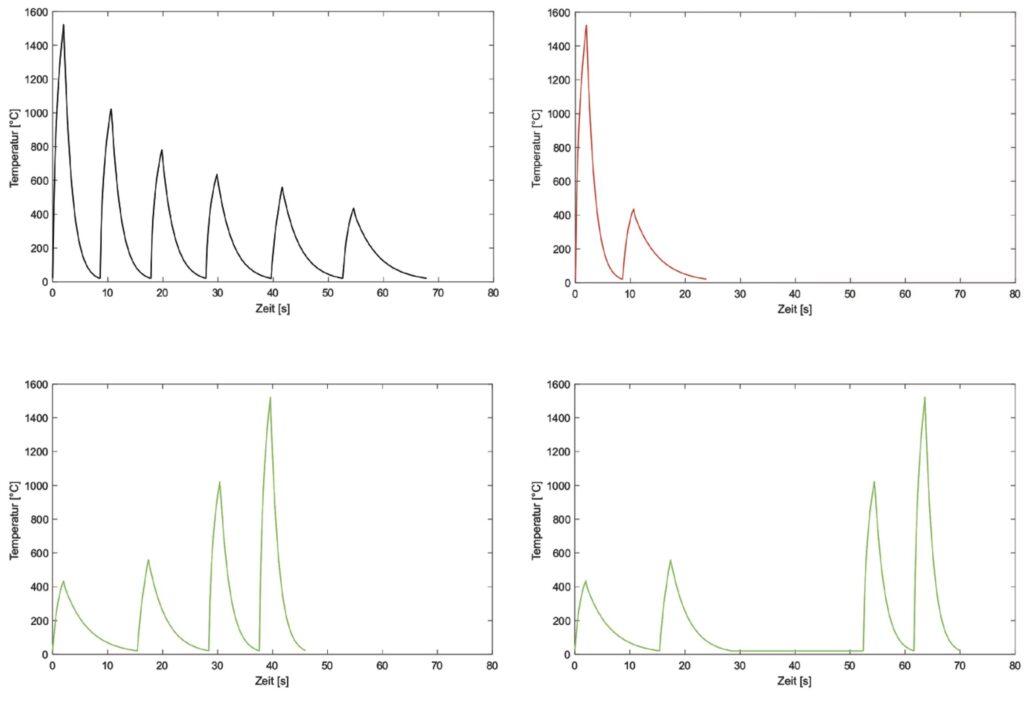
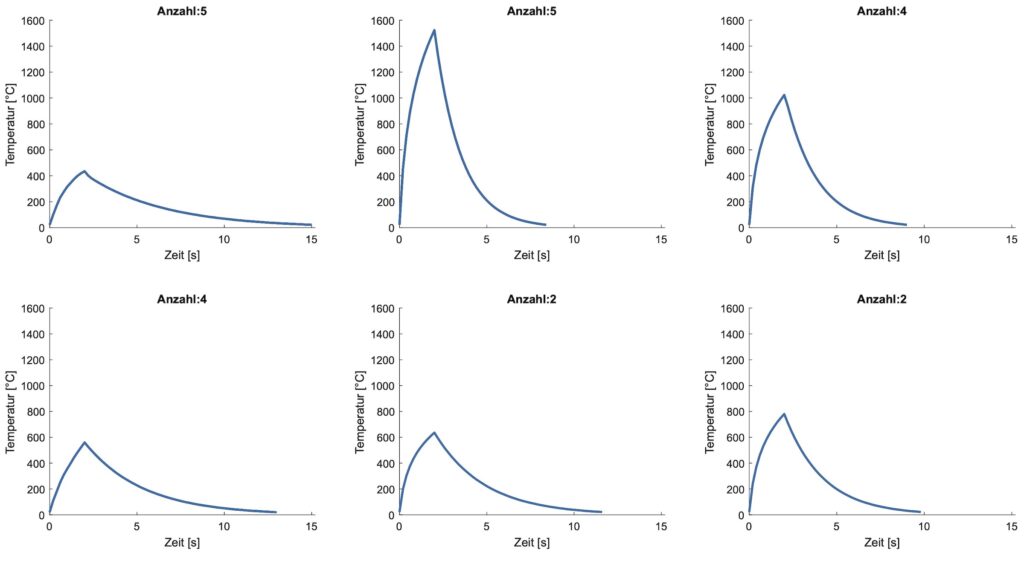
Die unterschiedlichen Temperaturverläufe für verschiedene Blechdicken an der Stanzkante sind in Bild 3 abgebildet. Diese Werte sind simulierte Daten, die auf den Berechnungen physikalischer Grundlagen basieren. Schließlich ist in Bild 5 die gesamte Zeitreihe abgebildet, welche sich durch mehrfaches Durchlaufen der vier Produktionsabläufe zusammensetzt.
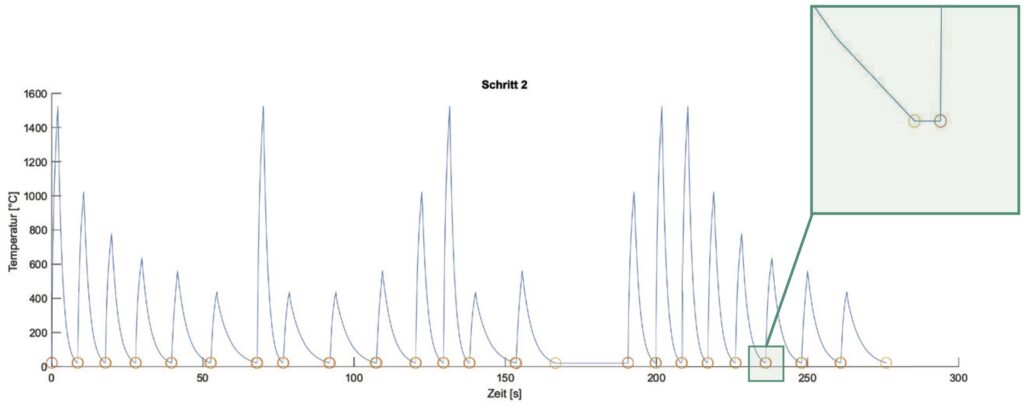
Insgesamt besitzt die gemessene Zeitreihe 1382 Datenpunkte, welche über eine Gesamtdauer von 267,2 Sekunden abgetragen sind. Die Abtastfrequenz beträgt 5 Hz.Um den Temperaturverlauf in Bearbeitungsmuster zu segmentieren, wird die lokale Minimasuche eingesetzt. Da die einzelnen Werkstücke des lasergestützten Stanzens sich ebenfalls durch die Temperatur der Umgebungstemperatur zu Beginn und am Ende beschreiben lassen, ist dieser Ansatz passend. Das Ergebnis der Suche nach lokalen Minima ist in Bild 6 dargestellt. Als Ergebnis resultierten 22 Bewegungsmuster, welche den Temperaturverlauf zwischen je zwei Minima darstellen.
Die in den beiden vorangegangenen Schritten extrahierten Muster werden in Algorithmusschritt 3 paarweise miteinander verglichen. Als Distanzmaß wurde die Manhattan Metrik gewählt. Die daraus resultierende Distanzmatrix ist in Tabelle 1 zu sehen.
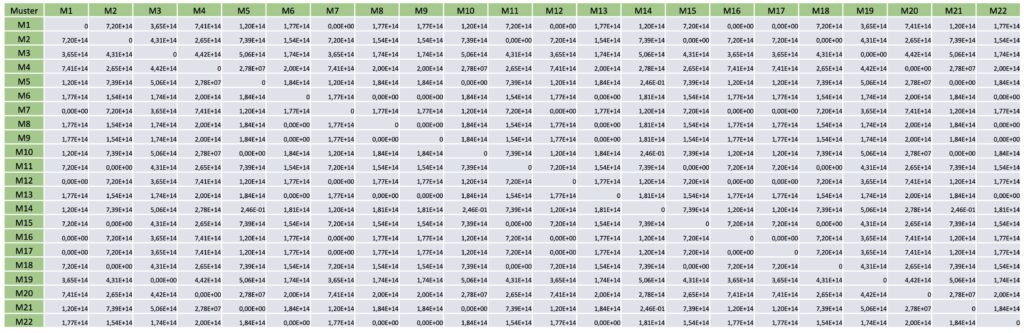
Auf Basis der durch Distanzberechnung erhaltenen Distanzmatrix wird ein Clusterverfahren durchgeführt. Ziel des Clusterverfahrens ist das Zuordnen gleicher oder leicht abweichender Bewegungsverläufe. Als Clusteralgorithmus wird ein dichtebasiertes Verfahren (Mean Shift-Clustering) verwendet.
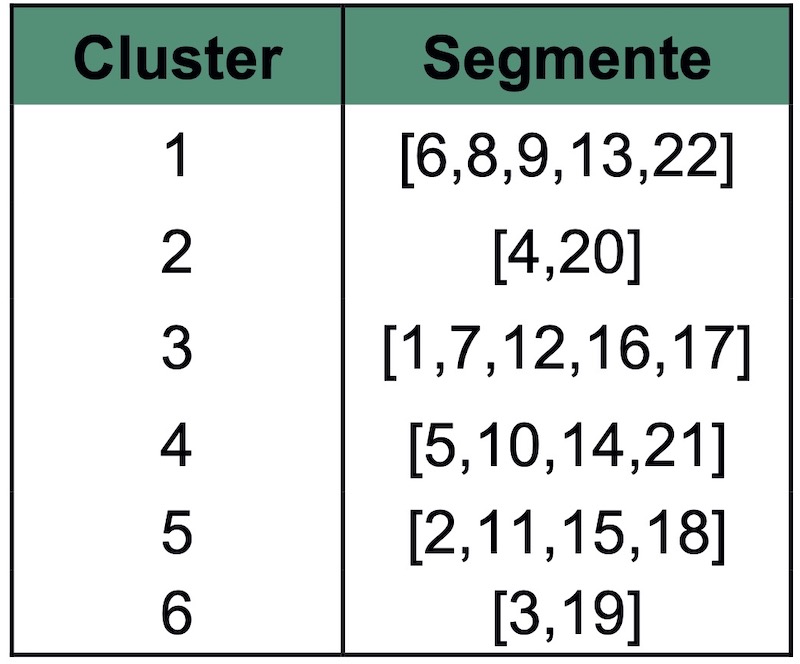
Ergebnis des Algorithmus sind sechs Cluster mit den jeweiligen, zugeordneten Bearbeitungssegmenten (siehe Tabelle 2) und deren Häufigkeit. Somit wurden alle sechs vorgegebenen Segmente erkannt und die Muster korrekt segmentiert.
Die einzelnen Verläufe der erkannten Bearbeitungssegmente decken sich mit den beschriebenen Subsequenzen für die unterschiedlichen Blechdicken. In Bild 7 ist die Ausgabe der Segmente als Temperaturverlauf erkennbar.
Ausblick
In vorliegendem Artikel ist ein Anwendungsfall der ersten Phase der Datensegmentierung alsBasis skalierbarer KI-Algorithmen vorgestellt. Durch diese Basisfunktion können KI-Modelle, wie bspw. zur Prozess- oder Qualitätsoptimierung und -überwachung prozess- und zustandsübergreifend angewendet und auf die gesamte Produktion übertragen werden. KI-Modelle müssen demnach keine Insellösungen mehr sein und werden auch für heterogene Anlagen in der Produktion breit anwendbar.
DOI: 10.30844/FS20-1_51-54
Literatur
[1] Gönnheimer, P.; Hillenbrand, J.; Betz-Mors, T.; Bischof, P.; Mohr, L. & Fleischer, J.: Auto-configuration of a digital twin for machine tools by intelligent crawling, 2019, Production at the leading edge of technology, Hrsg. Wulfsberg, J. P.; Hintze, W. & Behrens, B., S. 543-552[2] Netzer, M.; Michelberger, J.; Fleischer, J.: Intelligente Störungserkennung einer Werkzeugmaschine, 2019, ZWF 114 (2019), Carl Hanser Verlag GmbH & Co. KG, DOI 10.3139/104.112158
[3] Koegh, E.; Kasetty, S.: On the Need for Time Series Data Mining Benchmarks: A Survey and Empirical Demonstration. Data Mining and Knowledge Discovery 7 (2003) 4, S. 349 – 371 DOI: 10.1145/775047.775062 DOI: 10.1023/A:1024988512476
[4] Putz, M; Frieß, U; Wabner, M et al.: State-based and Self-adapting Algorithm for Condition Monitoring, Procedia CIRP 62 (2017 ) 311 – 316,https://doi.org/10.1016/j. procir.2016.06.073
[5] Grden, M.; Skkiettibutra, J.; Vollertsen, F.; Johnigk, C.; Emonts, M.; Brecher, C. & Eckert, M. (2010), „Prozessauslegung beim Laserstrahlunterstützten Stanzen“, Laser Technik Journal, Bd. 7, Nr. 6, S. 36–41.
Ihre Downloads
Branchen: Fertigung - HighTech Fertigung - Serie Fertigung - Varianten